Diagramy aktywności w modelowaniu workflow
„Workflow” to „buzzword” z gatunku tych nielicznych, które użyte w dobrze dobranym kontekście brzmią nawet lepiej niż „XML”. Precyzyjnie wstawione we właściwie uszy „workflow” może uzasadnić nawet przebudowanie od zera systemu dla klienta, który teraz sam już nie rozumie jak mógł dotąd funkcjonować nie znając tego zbawiennego pojęcia. I wcale nie mówię, że to źle, bo oprogramowanie procesów biznesowych bez „workflow” jest jak propagowanie tekstowego interfejsu użytkownika — może i wydajne, może i ergonomiczne, ale i tak bez szans na sukces komercyjny...
przepływ kontrolowany
Z czysto technicznego punktu widzenia niewiele można powiedzieć o „workflow” jako takim. Wiadomo tyle, że biznesowo-analityczny „przepływ pracy” trzeba zamodelować i oprogramować, więc jest do tego potrzebny jakiś mechanizm programowy w stylu „engine”. Istnieje jednak mnóstwo najróżniejszych implementacji we wszelkich możliwych technologiach, z różnymi wymaganiami, możliwościami i różnym stopniem integracji z innymi aplikacjami. W tym sensie pojęcie „workflow” jest niemal tak samo pojemne jak CMS (kolejny „buzzword” nawiasem mówiąc).
Na potrzeby dalszych rozważań wyobraźmy sobie, że istnieje mechanizm („engine”) realizujący ideę workflow, który posiada następujące cechy:[1]
- jest konfigurowalny w sposób stosunkowo prosty, zrozumiały i łatwy w obsłudze z poziomu aplikacji, np. za pomocą plików XML (co oczywiście nie wyklucza możliwości istnienia graficznego narzędzia do modelowania procesów),
- workflow jest opisany z pomocą procesów, które oprócz składników oczywistych (jak początek, koniec, decyzja, fork, join), posiadają dwa główne rodzaje węzłów:
- zadanie — element procesu, który wymaga akcji człowieka (w przypadku aplikacji — interakcji z użytkownikiem); wszystkie sygnały kierowane do procesu pozostającego w tym węźle są ignorowane do czasu jawnego zakończenia zadania przez człowieka,
- stan — zmienia właściwości (stan zmiennych) procesu; przejście do kolejnego węzła procesu nie wymaga akcji człowieka i następuje na podstawie wewnętrznych decyzji systemu,
- engine workflow daje się całkowicie zintegrować z aplikacją główną, lub też aplikacja jest budowana w oparciu o sterowanie workflow, co oznacza iż:
- węzły procesu mogą być opisane przez klasy lub metody, których wywołanie w odpowiednich momentach (również takich jak „początek zadania”, „koniec zadania”, „wejście w stan”, „przejście” itp.) jest zapewnione zgodnie z opisem procesu,
- węzły (zwłaszcza typu zadanie) muszą mieć możliwość przypisania klas umożliwiających przeprowadzenie interakcji z użytkownikiem aplikacji, np. poprzez wymianę parametrów formularza GUI ze zmiennymi procesu,
- węzły (zwłaszcza typu stan) muszą mieć możliwość przypisania klas umożliwiających wymianę danych zapisanych w zmiennych procesu z danymi aplikacji, np. poprzez wykonanie operacji na bazie danych.
Pomijając na razie problem oprogramowania takiego mechanizmu, warto się przede wszystkim zastanowić jak jego zastosowanie wpływa na projekt systemu informatycznego.
na granicy światów
Podstawowym problemem wynikającym ze stosowania mechanizmu workflow o powyższej charakterystyce jest fakt, że opis procesów leży na pograniczu analizy i projektu technicznego. Z jednej strony jest to „przepływ pracy” w rzeczywistości biznesowej, którą system informatyczny ma wspierać, więc jest to zagadnienie czysto analityczne — procesy powinny obrazować jak przebiega „biznes” klienta. Z drugiej jednak strony workflow związany jest z konkretnymi rozwiązaniami technicznymi — węzły procesu powinny prowadzić do konkretnych mechanizmów programistycznych. Stworzenie opisu procesu w sposób taki, by opis ten był przydatny zarówno dla analityków jak i projektantów (a może też programistów) jest, jak się niedawno przekonałem, zadaniem wcale nie trywialnym.
aktywność procesu
W projekcie, w którym ostatnio mam nieszczęście uczestniczyć, zaproponowałem analitykom przygotowanie opisu procesów w postaci diagramów aktywności UML. Być może bardziej naturalny dla analityka byłby opis za pomocą BPMN, jednak taką notację trzeba najpierw (po)znać (nie podejrzewam o to żadnego projektanta ani tym bardziej programisty) a poza tym standardowe UML-owe diagramy aktywności lepiej sprawdzają si na wspomnianej wyżej granicy światów — analitycznego i technicznego.
Koncepcję, którą stosujemy (na razie z powodzeniem) oparłem na kilku banalnie prostych założeniach:
- diagram aktywności UML wykorzystujemy do modelowania procesu workflow — wtedy jest tak samo dobry jak diagram BPMN, a nawet lepszy ;-),
- zachowujemy maksymalną abstrakcję od technologii i nie próbujemy opisywać szczegółów algorytmu lub uwzględniać wykonywalności programowej (uwaga: to trudne jeśli analityk ma doświadczenie programisty),
- definiujemy dwa podstawowe stereotypy dla akcji:
- stereotyp
<<U>>— akcje wymagające interakcji z użytkownikiem aplikacji; w procesie workflow są to zadania, a w praktycznej realizacji ekrany/strony aplikacji; koniec takiego zadania następuje w momencie naciśnięcia klawiszasubmitna ekranie, - stereotyp
<<S>>— akcje automatyczne, typu zmiany statusów i obliczenia; w workflow są to stany wpływające na zmienne procesu, a w praktyce obliczenia i decyzje podejmowane przez system,
- stereotyp
- zapisy do bazy danych oznaczamy jawnie jako element DataStore; w procesie workflow są to stany, które w praktycznej realizacji są opisane akcjami wykonującymi operacje na bazie,
- nie przeszkadza nam jeśli do akcji o stereotypie
<<U>>powracamy wielokrotnie z innych akcji o takim samym stereotypie — oznacza to po prostu powrót z ekranu podfunkcji do ekranu głównego, natomiast nie oznacza, że ekran ten jest pokazywany w postaci początkowej (pustej) tylko może być częściowo wypełniony na podstawie wcześniejszych działań użytkownika (przy zaożeniu zastosowania modelu MVC powiedziałbym: „na podstawie aktualnego stanu modelu”) — najlepiej jeśli na diagramie jawnie widać jakie dane są przekazywane (ObjectFlow).
W efekcie powstaje diagram aktywności, który faktycznie jest diagramem procesu workflow, a równocześnie zawiera informacje o wykorzystywanych ekranach i akcjach systemu w tym również o operacjach na bazie danych. Przy zastosowaniu tej koncepcji diagram aktywności procesu publikacji nowego wpisu na blogu mógłby wyglądać następująco:
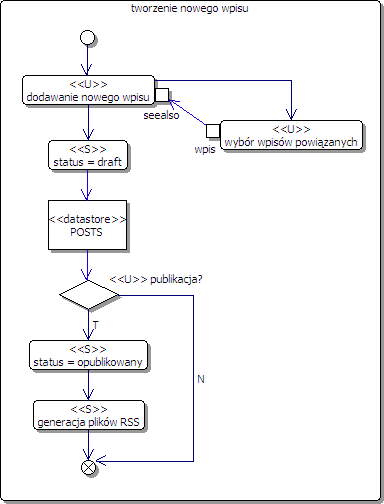
Rys.1. workflow action diagram
Proste? No jasne ;-) Co więcej, przy dobraniu odpowiedniego mechanizmu workflow jest to również łatwe to technicznego zaprojektowania i oprogramowania. Ale o tym już innym razem...
2005.10.07 | 2 komentarze | ![]()
tagi » technologie i rozwiązania, uml
Komentarze
#1 | 2005.10.07 17:32 | mmazur
A gdzie tu jest miejsce, że tak powiem na interfejs użytkownika?
Z mojego doświadczenia wynika, że jakiekolwiek systemy automatyzujące i usprawniające wykonanie jakiś czynności powinny zaczynać jako systemy bardzo proste robiące jedną, czy dwie rzeczy, żeby użytkownicy nie mieli z tym problemu.
Kiedyś z okazji jakiejś prezentacji Borlanda widziałem ich wielki system do zarządzania tworzeniem oprogramowania. To coś śledziło postępy, informowało mailem kogo trzeba o zmianach, oferowało kilka poziomów dostępu (zależnie od tego co użytkownik miał robić) i w ogóle było wielkim i skomplikowanym systemem.
I to było widać. Po uruchomieniu człowiek widział piętnaście pól tekstowych, drzewko z gigantyczną ilością elementów, jakieś dropdown boksy i ogólnie wszystkie możliwe kontrolki windowsowe. To *nie* jest prawidłowy sposób na robienie takich rzeczy, bo zapewne da się to używać w celu zwiększenia wydajności, acz jak dla mnie głównym zadaniem takiego systemu jest straszenie potencjalnych użytkowników.
Więc jeśli mamy stereotyp <<U>> ze sporą ilością danych do pobrania, to kto decyduje o rozdrobnieniu tego? Programista może rozdrobnić jakiś spory formularz na dwie części, ale takie schowanie połowy opcji w dodatkowo odpalanym okienku dialogowym zazwyczaj nie jest równoznaczne z ułatwieniem obsługi, a w/w programista nie ma poza takim rozwiąznaniem specjalnie wielkiego pola manewru.
#2 | 2005.10.10 08:03 | MiMaS
A gdzie tu jest miejsce, że tak powiem na interfejs użytkownika?
To jest, kolego, diagram workflow, tworzony przez analityka dla projektanta (ewentualnie wynik współpracy obydwu) obrazujący przebieg „sterowania” w jakimś fragmencie aplikacji. Przedstawione zadania dla użytkownika (te akcje ze stereotypem <<U>>) mówią gdzie zostanie wykorzystany interfejs dla człowieka i gdzie będzie przeprowadzona z człowiekiem interakcja. Dwa takie zadania to dwie rozróżnialne w analizie interakcje. Ani słowa więcej na ten temat (czy to na pewno jeden ekran, czy może wiele, czy to formularz WWW czy może okno aplikacji desktopowej), bo to jeszcze nie czas i nie ten poziom abstrakcji. Do programisty stąd jeszcze bardzo daleko. W ogóle wątpię, czy programista zobaczy ten diagram.
Więc jeśli mamy stereotyp <<U>> ze sporą ilością danych do pobrania, to kto decyduje o rozdrobnieniu tego?
Oczywiście decydował będzie projektant (nie programista, programista nie jest od decydowania o takich sprawach!) w następnych krokach projektu. W praktyce to powinno być tak, że przedstawione powyżej akcje <<U>> powinny być jakoś nazwane/ponumerowane a w dalszej części projektu znajdzie się opis ich implementacji zawierający projekt (może nawet prototyp) odpowiednich ekranów oraz diagramy sekwencji pokazujące jakie klasy są zaangażowane w obsługę tego/tych ekranu/ekranów (czyli gdzie i jakie kontrolery, jak współpracują z klasami modelu, gdzie jest styk z warstwą DAO itd. itp.).
Doprawdy problem organizacji interfejsu wydaje mi się na tym etapie zupełnie marginalny i dosyć odległy. A w ogóle pomysł, że programista może zacząć pisać kod na podstawie powyższego diagramu jest dosyć karkołomny, żeby nie powiedzieć samobójczy ;-)
Uwaga: Ze względu na bardzo intensywną działalność spambotów komentowanie zostało wyłączone po 60 dniach od opublikowania wpisu. Jeżeli faktycznie chcesz jeszcze skomentować skorzystaj ze strony kontaktowej.