Szukajcie a znajdziecie?
Google jest do dupy i tyle. Co z tego, że to najlepsza dzisiaj wyszukiwarka internetowa, skoro i tak jest to program żałośnie wręcz tępy. Zupełnie nie spełnia moich oczekiwań i wyobrażeń na temat wyszukiwania informacji w Internecie...
błądzenie w ciemnościach
Problem jest oczywisty, wspominałem zresztą o tym kiedyś — wyszukiwarki początku XXI wieku nie mają bladego pojęcia czego właściwie mają szukać i z rozpaczy czepiają się jakiegokolwiek punktu zaczepienia, pisowni słów, podobnego ciągu liter, czegokolwiek. Zupełnie nie mają pojęcia o semantyce i kontekście znaczeń.
Przykład: słowo „ankh”. Wyszukiwarka, którą widzę oczami wyobraźni, nie szukałaby bezmyślnie wszystkich stron, gdzie słowo takie występuje, tylko zaczęłaby od próby uściślenia — czy użytkownik ma na myśli:
- starożytny symbol egipski w formie krzyża z pętlą,
- polski zespół muzyczny z początku lat 90-tych ubiegłego wieku, ewentualnie płyty tegoż,
- rzekę Ankh na Dysku w świecie wykreowanym przez Terrego Pratchetta, ewentualnie miasto Ankh-Morpork leżące nad tą rzeką,
- czy może jeszcze coś innego?
Dopiero po udzieleniu odpowiedzi na takie pytanie jest sens sięgać do przepastnej bazy i wygrzebywać z niej informacje o „ankh” w zadanym kontekście: „ankh-symbol”, „ankh-rzeka”, „ankh-zespół”. Wcześniej jakiekolwiek szukanie jest po prostu stratą czasu, mocy obliczeniowej maszyny i cierpliwości użytkownika — większość wyników będzie od razu nadawała się do śmieci, bo pytającemu nie o to „ankh” chodziło.
światło w tunelu
Wbrew pozorom wyszukiwarka realizująca takie założenia wcale nie jest wymysłem futurologa. No bo czego właściwie potrzeba... Po pierwsze wyszukiwarka musi „mieć świadomość”, że słowo podane jej przez użytkownika może mieć wiele znaczeń. Ba, że w ogóle ma jakieś znaczenie. Nie wymagam jednak od żadnego programu zgadywania znaczenia słów ani wykazywania się jakąkolwiek formą sztucznej inteligencji — myślące maszyny pozostawmy filmowcom. W Internecie cała wiedza o świecie, jaką posiada wyszukiwarka, pochodzi z informacji zebranych z tej sieci właśnie. Zatem lista możliwych znaczeń danego słowa powinna pochodzić również z tej samej sieci, czyli musi być dostarczona przez autorów poszczególnych stron/dokumentów — na zasadzie „jeśli o czymś piszesz, wyjaśnij o co ci właściwie chodzi”. Taki opis semantyki pojęć, w przeciwieństwie do lansowanej dziś semantyki (sic!) znaczników, daje informację o czym jest dany tekst, a nie tylko jak jest. Myślę, że dla profesjonalnych twórców stron wymaganie dostarczenia takich informacji byłoby do zaakceptowania. Zwłaszcza, jeśli istniałyby programy ułatwiające odnalezienie i wskazanie kontekstu znaczeń w jakim jest osadzony dany tekst publikowany w Sieci.
Co ciekawe wszystkie technologie wymagane do oprogramowania takiego zachowania już istnieją. I to nawet w postaci oficjalnych rekomendacji W3C. Mówię oczywiście o RDF i OWL; do opisania szczegółowej semantyki dowolnego zasobu opisywa(l)nego w Sieci nie potrzeba nic więcej. Wystarczy, żeby na stronach zaczęły się pojawiać informacje czytelne nie tylko dla człowieka, ale również dla maszyny (agentów programowych) — równocześnie z informacją idzie w świat wskazanie ontologii wyjaśniającej o czym właściwie dana informacja mówi. Google (jako przedstawiciel nowoczesnych współczesnych wyszukiwarek) poradziłby sobie z taką informacją zapewne bardzo szybko (uwzględniając ogólną prężność Google Inc. i inicjatywy typu Google Base, która to baza przez możliwość dowolnego definiowania typu dodawanego zasobu stanowi prawie gotową bazę semantyczną).
niestety światło samo się nie zapali
Wychodzi więc na to, że ułomność współczesnych wyszukiwarek jest spowodowana pośrednio niezdolnością autorów stron do publikowania semantycznego opisu informacji w sposób zrozumiały dla agentów zbierających dane. Niby jest oczywiste, że użytkownikiem Internetu jest dzisiaj nie tylko człowiek, a coraz częściej najróżniejsze maszyny/programy, a równocześnie notorycznie ignorujemy ten fakt i publikujemy tylko dla ludzi. Właściwie jedyne maszyny jakim cokolwiek ułatwiamy w naszym WWW to agregatory RSS-ów czy inne tam pingbacki. Niby już coś, ale ciągle mało.
Faktycznie jednak problem ten nie jest banalny. Rozwiązania typu Embedded RDF wydają się słabe, a publikowanie osobno informacji (X)HTML dla człowieka i RDF dla maszyny — zbyt pracochłonne. Jednak jakiekolwiek by nie było ostateczne rozwiązanie, na pewno leży ono po stronie autorów stron WWW (czy może WWW/SW). Szczerze mówiąc, to trochę studzi moje zapędy i powoli zaczynam się obawiać, że sensowną wyszukiwarkę dostanę nie jutro, a dopiero pojutrze... :-/
A nawiasem mówiąc, strasznie bez sensu w tym kontekście wydają mi się działania magików od SEO — specjalizują się w wykorzystywaniu słabości niedorobionego mechanizmu, czyli w czymś, co historycznie rzecz biorąc w ogóle nie ma żadnego znaczenia i powinno być zrobione zupełnie inaczej. Za parę lat będziemy się śmiać z ich wysiłków... ;-)
patrz również:
2006.02.13 | 14 komentarzy | ![]()
tagi » semantic web, teorie i przemyślenia
Komentarze
#1 | 2006.02.13 09:33 | nbw
Ciekawym pomysłem jest Google Site Map, aczkolwiek to za mało.
Pół biedy, kiedy wyszukujemy słów. Problem rodzi się, gdy wyszkujemy obrazów. Tu już jest pełna dowolność, bo Google liczy na to, że użytkownik wystawiający grafikę nazwie ją np "ankh". Ale przecież, użytkownik może po prostu wrzucić hurtem tekst i obrazki będą miały nazwy DCxxyyeezz. Dla użytkownika będzie to oczywiste, że to ankh, dla odwiedzającego stronę - również. Dla wyszukiwarki - wcale.
Technologia to nie wszystko - ta istnieje od bardzo dawna. Teraz trzeba przekonać ludzi, by z niej korzystali.
A seOwce? Mijają się z powołaniem
#2 | 2006.02.13 10:05 | MiMaS
W e-mailu (dlaczego nie komentarz? nie ma się czego wstydzić ;-)), który dostałem przed chwilą kolega Przemek wskazuje na ciekawe rozwiązanie prezentacji wyników zastosowane w wyszukiwarce Clusty. Wyniki są tam grupowane w zależności od ich znaczenia, które wyszukiwarka wydedukowała ze strony. Metoda inna, niekoniecznie całkowicie sprawna (brak zastosowania ontologii uniemożliwia odwołanie się do konkretnego „klastra” w jakimś innym miejscu/konteście), ale przynajmniej sposób prezentacji jakoś tam zbliżony do moich wyobrażeń :-)
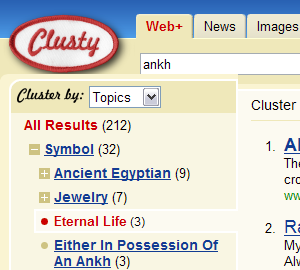
#4 | 2006.02.13 11:35 | Jarek
Rzeczywiście ciekawa wyszukiwarka. Żeby coś takiego miało teraz Google, ze swoją bazą zindeksowanych stron.
#5 | 2006.02.13 13:29 | kuba
nie do konca chwytam zagadnienie poruszane w tym tekscie. chodzi o definiowanie pojec dla wyszukiwarki tak? ale ktore pojecia wybrac z tekstu?
istnial kiedys poglad, ze wypowiedzi politykow bylyby klarowniejsze gdyby ci definiowali pojecia ktorych uzywaja. mialby to uczynic jezyk bardziej jednoznacznym. karl popper udowodnil ze defiowanie wszystkich pojec uczyniloby wypowiedz jeszcze metniejszą.
jezyk naturalny ma to do siebie, ze jest nieprecyzyjny i wieloznaczny. roboty posluguja sie sztucznym jezykiem. oba te rodzaje jezykow sie przystaja do siebie wiec chetnie dowiedzialbym sie dokladniej na czym mialoby polegac to definiowanie. znaczy sie jak pisac dla robota
pozdrawiam
ps. na prawde ciekawy tekst i serio prosze o wiecej
#6 | 2006.02.13 13:49 | MiMaS
chodzi o definiowanie pojec dla wyszukiwarki tak?
Nie tylko dla wyszukiwarki, lecz dla dowolnego agenta programowego działającego na rzecz dowolnej sprawy, w której jest potrzebna jakaś informacja. Wyszukiwarka taka jak dziś to małe piwo — chodzi raczej o zastąpienie dzisiejszego Internetu, czyli sieci dokumentów strawnych tylko dla ludzi, siecią danych — Semantic Web. Wtedy Internet stanie się (już się staje powolutku) nie tylko zbiorem powiązanych dokumentów HTML lecz faktycznie globalną otwartą bazą danych i wiedzy, z której korzystanie nie będzie wymagało posiadania mózgu homo sapiens sapiens. Tak w skrócie ;-)
jak pisac dla robota
Oczywiście nie wolnym tekstem tylko za pomocą RDF z wykorzystaniem dobrze zdefiniowanych ontologii...
Podejrzewam, że działa tutaj w tej chwili „wykop efekt”, ale nie liczcie, że będę z tej okazji publikował dogłębne wyjaśnienia dla każdego przypadkowego przechodnia. Proszę o Waszą wyrozumiałość w tej kwestii. Zapraszam za to do innych wpisów w tej kategorii, może na początek do tego.
#7 | 2006.02.13 13:49 | Konlin
To i ja dorzucę coś od siebie - http://carrot.cs.put.poznan.pl. Zwraca o wiele więcej grup niż Clusty.
#8 | 2006.02.13 15:26 | DrLex
Rozumiem frustrację autora i szukanie punktu zaczepienia w semantycznym webie. Jednak nie jest tak różowo. Pisałem już o tym w meta utopii. Dopóki za ontologie i metadane będą odpowiedzialni ludzie, nic z tego nie będzie :(
#9 | 2006.02.13 17:30 | pawel
Google (oraz pozostałe wyszukiwarki oczywiście) ma niestety za zadanie porządkowanie śmietnika informacyjnego na którym bazuje. Garbage in - garbage out...
Ze szczątkowej sematyki HTML (DL+DT+DD) korzysta polecenie "define:" (google.com/search?q=define%3Aankh) - fajne było by wyświetlenie znalezionych definicji przy wynikach wyszukiwania wraz z linkiem "exclude" pozwalającym ze zbioru wyników usunąć strony, na których słowo występuje jedynie w kontekście wynikającym z definicji.
Cała idea dostarczania maszynom meta-danych jest fajna, ale przy założeniu że dane te będą dostarczać jedynie ludzie odpowiedzialni. Jednak przećwiczyliśmy to już z <meta name="keywords" /> - wynalazek, który mógł wspomóc indeksowanie dzięki zabiegom "specjalistów" stał się bezużytecznym śmieciem i poszedł do lamusa. Nie mamy gwarancji, że ludzie o podobnym podejściu nie zniweczą idei semantycznej sieci - podkładanie robotom bzdurnych definicji na szeroką skalę aby wywindować się na czołówki wyników może zaowocować bardzo podobnymi problemami jak dopisywanie bezsensownych słów kluczowych.
Wiem, że brzmi to nieciekawie, ale to walka o portfele użytkowników Sieci. Jeśli marketongowcom nie drży ręka przy okłamywaniu ludzi, to wciskanie kitu robotom przyjdzie im zupelnie bezrefleksyjnie.
#10 | 2006.02.14 08:58 | [trackback]
W komentarzach do poprzedniego wpisu pojawiły się dwie interesujące opinie (#8, #9), które zasługują na szerszą odpowiedź...
#11 | 2006.02.16 02:28 | [trackback]
Cluster searching @ Riddle's Jogger
[…] Natomiast niedawno właśnie po przeczytaniu zżymania się na Google u Świątkiewicza w komentarzach natrafiłem na szukarkę Clusty. Clusty to brat czy może dziecko Vivisimo przeznaczony do powszechnego użytku. […]
#12 | 2006.06.18 11:10 | Optyk
Czy moglibyści mi podać jakies przykłady stron www na ktorych informacje zapisane sa w ontologii.Jakies linki prosze przesylac na email:
optykus@interia.pl
Z gory bardzo dziekuje.
#13 | 2006.08.16 13:52 | Malwina
google są poryte szukam już ile czasu jednego utworu a tu gówno
Uwaga: Ze względu na bardzo intensywną działalność spambotów komentowanie zostało wyłączone po 60 dniach od opublikowania wpisu. Jeżeli faktycznie chcesz jeszcze skomentować skorzystaj ze strony kontaktowej.