Łączenie grafów RDF w praktyce
Resource Description Framework jako sposób opisu modelu danych nadaje się do zapisu dowolnych informacji. Sposób konstrukcji wyrażeń RDF (podmiot, predykat, obiekt) można bardzo łatwo dostosować do dowolnych danych, dla których można sobie wyobrazić wyrażenia (zasób, cecha, wartość). Czyli ... praktycznie dla wszystkich. :-) Nie bez powodu niektórzy tłumaczą RDF jako „Reusable Data Format”.
Ponieważ RDF to graf, który jest z założenia „sieciowy” i funkcjonuje w świecie otwartym, bardzo szybko pojawia się możliwość i potrzeba łączenia grafów pochodzących z najróżniejszych źródeł. Dopiero powstający w ten sposób zagregowany model RDF ujawnia sens całej zabawy i siłę unormowanego formatu opisu dowolnych danych. Jednak aby dokonać łączenia grafów w praktyce trzeba znać semantykę użytych wyrażeń (czyli zatrudnić mechanizmy OWL, nieraz mocno zaawansowane) albo ... zastosować jakieś arbitralne reguły i połączenia zdefiniowane wprost w momencie pozyskiwania danych.
Myślę, że w codziennym (u)życiu częściej stosuje się łączenie różnych danych za pomocą wyrażeń podawanych „z palca”. Jest to sytuacja zupełnie analogiczna jak w przypadku relacyjnych baz danych — to, jakie wyrażenia następują po WHERE w zapytaniu SELECT, jest słodką tajemnicą jego twórcy, tak samo w przypadku zapytania SQL jak w przypadku SPARQL.
sposób — rules
W przypadku Sieci Semantycznej mamy jeszcze jedną możliwość, nie występującą w środowiskach baz danych. Skoro RDF umożliwia zapisywanie wszelkich danych, to oznacza, że również wyrażeń logicznych i reguł. Jak wszystko w RDF są to wyrażenia trójkowe, np.
:przesłanka log:implies :wniosek .
przy czym zarówno przesłanka jak i wniosek są same w sobie również trójkami RDF. Aktualnie nie istnieje co prawda oficjalny standard zapisu takich konstrukcji za pomocą formatu RDF/XML (co tylko potwierdza zdanie, że RDF to nie XML[1]), ale nic nie stoi na przeszkodzie aby zapisać je w notacji N3.
Reguły takie mogą opisywać cokolwiek, np. ... zasady wyznaczania punktów wspólnych łączonych grafów. Jak każde inne wyrażenia, stanowią one część modelu, ale jednocześnie mogą zostać wykorzystane do modyfikowania jego zawartości. Mamy zatem w samym modelu/zbiorze danych informację o tym jak należy przeprowadzić jego agregację. Wystarczy dysponować (względnie) prostym mechanizmem wnioskującym...
realizacja — kombinowanie
W praktyce jest to dosyć proste, chociaż nie takie eleganckie i oczywiste jak być powinno. Trik najczęściej polega na wykorzystywaniu najróżniejszych zależności, niekoniecznie dosłownych i szczerze mówiąc nawet niekoniecznie poprawnych — zupełnie podobnie jak w SQL-u.
Przykładowo: wspominałem niedawno o częstym zwyczaju dodawania nadmiarowych informacji do opisu znanych osób w plikach FOAF, np. foaf:mbox lub foaf:mbox_sha1sum. Wartość ta lepiej niż np. foaf:name czy rdf:seeAlso nadaje się do pełnienia roli identyfikatora osoby — adres e-mail jest dosyć jednoznacznie przypisany odbiorcy, wbrew pozorom bardziej jednoznacznie niż nazwa/nazwisko, a na pewno bardziej niż adres pliku o danej osobie wspominającego. Można więc chyba zaryzykować i stworzyć regułę, wg której dwa zasoby posiadające ten sam adres e-mail są tożsame. W zapisie N3 wyglądałoby to tak:
@prefix log: <http://www.w3.org/2000/10/swap/log#> .
@prefix owl: <http://www.w3.org/2002/07/owl#> .
@prefix foaf: <http://xmlns.com/foaf/0.1/> .
this log:forAll :x, :y, :m.
{ :x foaf:mbox_sha1sum :m . :y foaf:mbox_sha1sum :m }
log:implies
{ :x owl:sameIndividualAs :y } .
lub z użyciem symboli skróconych:
@prefix foaf: <http://xmlns.com/foaf/0.1/> .
{ ?x foaf:mbox_sha1sum ?m . ?y foaf:mbox_sha1sum ?m } => { ?x = ?y } .
Po polsku: jeżeli zasób x ma foaf:mbox_sha1sum równy m oraz zasób y ma foaf:mbox_sha1sum równy m, to zasób x jest tym samym co zasób y.
Inny przykład: ontologia Pet, opisująca zwierzęta domowe, została zbudowana z myślą o wykorzystaniu łącznie z FOAF. W praktyce często jest tak, że osobny dokument opisuje osobę, z osobny zwierzaka. W dokumencie opisującym osobę (zapewne typu foaf:PersonalProfileDocument) znajduje się wyrażenie pet:hasPet ze wskazaniem na dokument opisujący zwierzaka (zapewne typu pet:PetProfileDocument), natomiast w tym drugim wskazanie na właściciela poprzez wyrażenie pet:fedBy. Połączenie tych dwóch faktów jest mówiąc szczerze dosyć karkołomne... Reguła jaką sobie dzisiaj na tę okazję wymyśliłem może wyglądać np. tak:
@prefix foaf: <http://xmlns.com/foaf/0.1/> .
@prefix pet: <http://purl.org/stuff/pets/> .
# jakis zwierzak p1 ma jakis profil
# i tego profilu glowym tematem jest zwierzak p2
# to p1 jest tym samym co p2
{ ?p1 a pet:Pet . ?p1 pet:hasProfile ?d .
?d a pet:PetProfileDocument . ?d foaf:primaryTopic ?p2 .
} => { ?p1 = ?p2 } .
efekt — cwm
Powyższe można łatwo przetestować np. za pomocą narzędzia cwm. Po wrzuceniu obu przedstawionych wyrażeń N3 do pliku rules.n3 i wydaniu w katalogu z moim profilem FOAF polecenia:
cwm --rdf foaf.rdf kalma.rdf maurycy.rdf --n3 --think=rules.n3
otrzymujemy graf RDF zawierający co prawda sporo nadmiarowych wyrażeń owl:sameAs, ale generalnie prezentujący połaczoną zawartość trzech plików RDF. Po wycięciu nadmiarowych i zaciemniających szczegółów (nieistotnych dla tego przykładu, głównie danych o mnie z foaf.rdf) graf[2] wygląda tak:
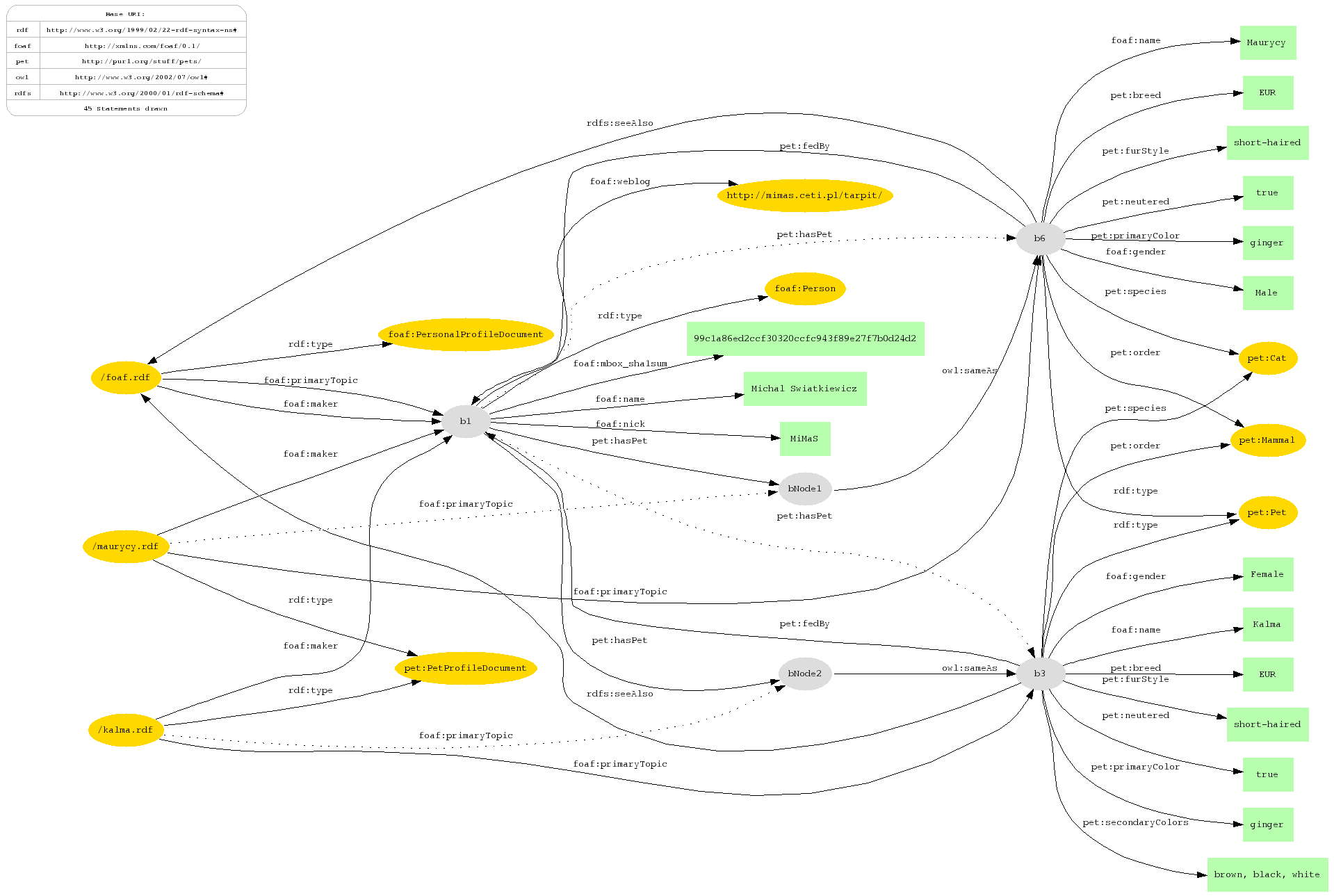
Rys.1. Graf RDF po połączeniu
Jak widać cel, czyli połączenie 3 grafów RDF w jeden i uzupełnienie go o wyraźne powiązania między mną a moimi zwierzakami, został osiągnięty. :-)
[1] RDF/XML to tylko jeden z wielu możliwych sposobów serializacji grafu RDF — nie jedyny i nie najlepszy...
[2] Obrazek został wygenerowany przez dot z pakietu Graphviz za pośrednictwem RAP. Linie przerywane oznaczają wyrażenia wywnioskowane przez RAP (na podstawie owl:sameAs) czyli efekt dalszej obróbki powstałego RDF-a; nie było ich w pliku wyjściowym z cwm.
2006.01.02 | skomentujesz? | ![]()
tagi » semantic web, narzędzia, technologie i rozwiązania, rdf, cwm
Komentarze
Brak komentarzy do tego wpisu.
Uwaga: Ze względu na bardzo intensywną działalność spambotów komentowanie zostało wyłączone po 60 dniach od opublikowania wpisu. Jeżeli faktycznie chcesz jeszcze skomentować skorzystaj ze strony kontaktowej.